1. Introduction
Neural networks struggle with length generalization: a model trained on sequences of length $L$ typically fails when tested on sequences of length $L' \gg L$. Transformer-based architectures, despite their empirical success across natural language processing, rely on global attention mechanisms that scale quadratically with sequence length and offer no structural guarantee that computation learned at one scale will transfer to another.
Current approaches to this problem are largely empirical: positional encoding modifications, data augmentation strategies, curriculum learning. They lack a principled foundation that explains why generalization should or should not occur. We argue that the failure of length generalization is not a deficiency of particular architectures but a consequence of violating fundamental physical constraints on information processing.
This paper proposes three physics-inspired postulates — relativistic causality, spacetime symmetry, and dissipation — and shows that any architecture satisfying all three necessarily takes the form of a neural cellular automaton. We call the resulting architecture SEAD (Spatiotemporal Evolution with Attractor Dynamics). The postulates are not merely sufficient conditions for generalization; they provide a physical explanation for why it occurs.
We validate SEAD on three tasks that span a range of computational complexity: the parity function, integer addition, and Rule 110 cellular automaton simulation. On parity, SEAD achieves perfect length generalization via light-cone propagation. On addition, training on $L = 16$ yields 100% accuracy at $L = 1{,}000{,}000$. On Rule 110, a Turing-complete CA, SEAD learns the update rule without divergence.
2. Three Postulates
We begin from a simple observation: physical systems that process spatially extended information — from crystal growth to fluid dynamics to biological neural networks — all obey certain universal constraints. We distill these into three postulates and ask: what is the most general neural architecture that satisfies all three?
2.1 Relativistic Causality (Locality)
Postulate 1. Information propagates at finite speed. The update of any cell depends only on a fixed-size local neighborhood, independent of the total system size.
In physical systems, causality is local: no signal travels faster than a finite maximum speed. In the context of sequence processing, this means the state at position $i$ and time $t+1$ can depend only on positions within some fixed radius $r$ at time $t$:
$$h_{t+1}(i) = f\bigl(h_t(i-r), \ldots, h_t(i), \ldots, h_t(i+r)\bigr)$$This is the defining constraint of a cellular automaton. It immediately excludes architectures with global receptive fields (such as full attention) from satisfying this postulate. Information about distant positions can still influence a cell, but only after sufficiently many time steps — propagating through a light cone, exactly as in relativistic physics.
The practical consequence is that the receptive field is fixed at architecture time and does not grow with input length. This is what makes length generalization structurally possible: the update rule never "sees" the total sequence length, so it cannot overfit to it.
2.2 Spacetime Symmetry
Postulate 2. The update rule is translation-invariant: the same function is applied at every position and at every time step.
This postulate has two components. Spatial translation invariance means that the update rule does not depend on absolute position — it is shared across all cells (weight sharing). Temporal translation invariance means the same rule applies at every time step — there is no layer-dependent parameterization.
Spatial symmetry is the neural-network analogue of Noether's theorem: translation invariance in space implies conservation of a corresponding quantity. In practice, it means that patterns learned at one position automatically transfer to all other positions. A model that uses different weights at different positions (such as a Transformer with learned positional encodings) breaks this symmetry and must re-learn the same computation at each position.
Temporal symmetry excludes deep feedforward networks, where each layer has independent parameters. A system satisfying this postulate has a single rule applied iteratively, not a sequence of distinct transformations. The number of iterations is not fixed at architecture time; the system runs until it converges.
2.3 Dissipation and Stability
Postulate 3. The dynamical system must converge to a stable attractor. The update rule includes a dissipative mechanism that prevents unbounded growth of activations.
An iterative system that applies the same rule indefinitely can diverge: activations may grow without bound, oscillate, or exhibit chaotic behavior. Physical systems avoid this through dissipation — energy loss that drives the system toward equilibrium.
In SEAD, dissipation is implemented through the sigmoid activation function $\sigma$, which bounds all state values to $(0, 1)$. This is not merely a nonlinearity; it is a contraction that ensures the iterative dynamics have a fixed point. The system evolves toward an attractor state that encodes the answer; the answer is read out only after convergence.
This "relax-and-project" mechanism — iterate until convergence, then read out — stands in contrast to feedforward architectures that produce an answer in a single pass. The number of relaxation steps adapts to the difficulty of the input: simple inputs converge quickly, complex inputs require more steps, and the architecture imposes no upper bound.
3. The SEAD Architecture
The three postulates jointly determine the architecture. Any neural network satisfying Postulates 1–3 is necessarily a neural cellular automaton with shared weights, bounded activations, and iterative convergence. We call the resulting architecture SEAD.
In its 1D form, SEAD operates on a sequence of cells $h_t(i) \in \mathbb{R}^C$, where $C$ is the number of state channels. At $t = 0$, the grid is initialized to a uniform state. At each step, the update rule is:
$$h_{t+1}(i) = \sigma\!\Bigl(W_h \cdot \mathrm{relu}\bigl(W_2 \cdot \mathrm{relu}(W_1 \cdot [\mathbf{e}_i;\, W_s\, h_t(i)])\bigr)\Bigr)$$where $\mathbf{e}_i$ is the learned embedding of the token at position $i$, $W_s$ projects the current state into the embedding space, $W_1$ is a local convolution kernel (radius $r$) that gathers neighborhood information, $W_2$ is a pointwise nonlinear transformation, $W_h$ is the output projection, and $\sigma$ is the sigmoid.
By construction, this architecture satisfies all three postulates:
- Causality: $W_1$ is a local convolution with fixed kernel size; the receptive field per step is $2r + 1$ and does not depend on input length.
- Symmetry: All weights ($W_1, W_2, W_h, W_s$) are shared across positions and time steps. Token identity enters only through the embedding $\mathbf{e}_i$, not through position-dependent parameters.
- Dissipation: The sigmoid bounds all activations to $(0, 1)$, ensuring the iterative dynamics contract toward a fixed point.
At inference time, the NCA iterates until convergence: $\max |h_{t+1} - h_t| < \epsilon$. The answer is read from a designated output cell after the system has relaxed to its attractor. Training uses a variable number of steps sampled uniformly, forcing the model to produce correct outputs at any iteration depth beyond a minimum.
4. Experiments
We evaluate SEAD on three tasks chosen to span a range of computational complexity: parity (a function computable by finite automata augmented with a single counter), addition (an algorithm requiring carry propagation), and Rule 110 (a Turing-complete cellular automaton). In each case, we train on short sequences and test on sequences far beyond the training distribution.
4.1 Parity
The parity function computes the XOR of a binary input sequence. Despite its simplicity, it is a canonical test of length generalization: the answer depends on every input bit, and no shortcut based on local statistics can solve it for arbitrary lengths.
SEAD achieves perfect length generalization on parity. The mechanism is transparent: information propagates through the 1D grid as a light cone, with the parity signal traveling at one cell per time step from each end of the sequence toward the readout position. The number of convergence steps scales linearly with input length, exactly as predicted by the finite propagation speed of Postulate 1.
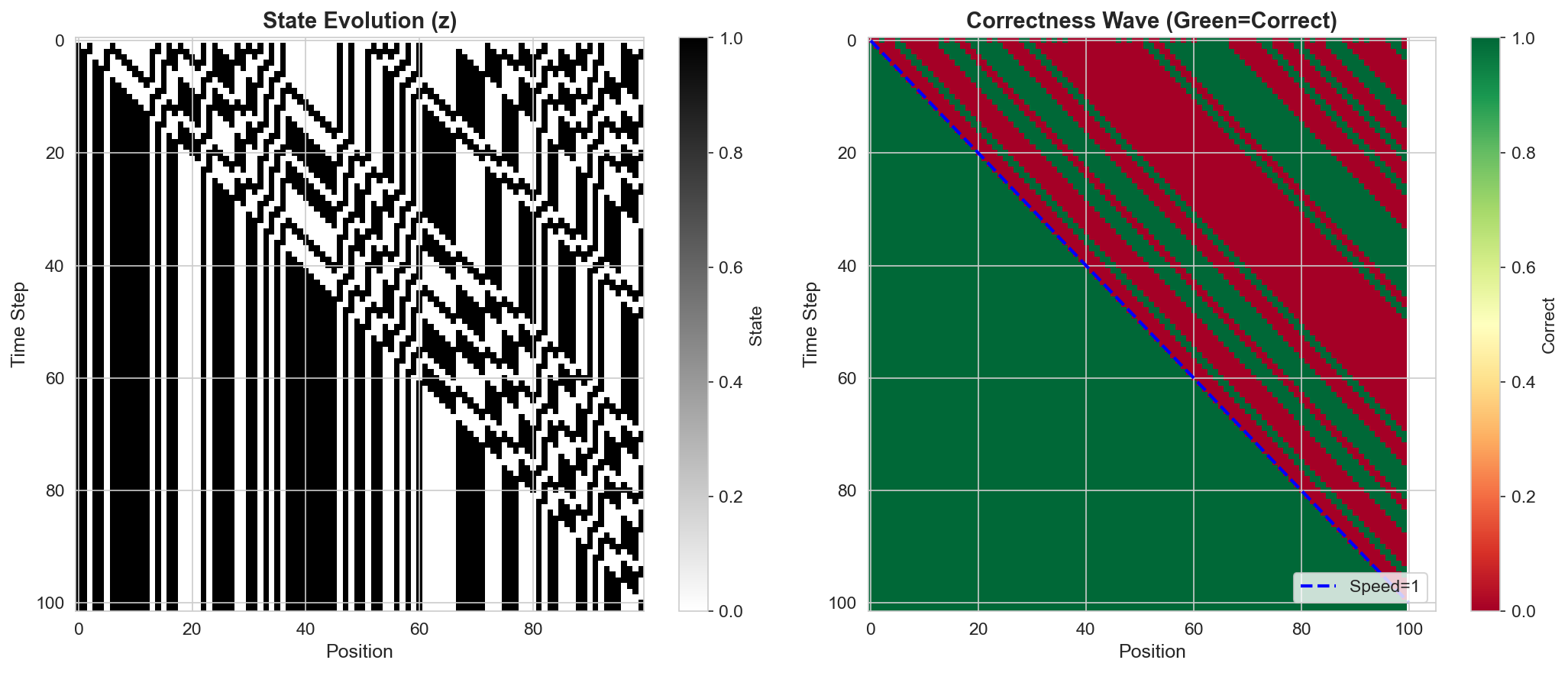
4.2 Addition
Integer addition requires carry propagation across the full length of the operands. We train SEAD on addition of numbers with $L = 16$ digits and test on inputs up to $L = 1{,}000{,}000$ digits. SEAD achieves 100% accuracy across the entire range — a scale-invariant generalization spanning five orders of magnitude beyond the training distribution.
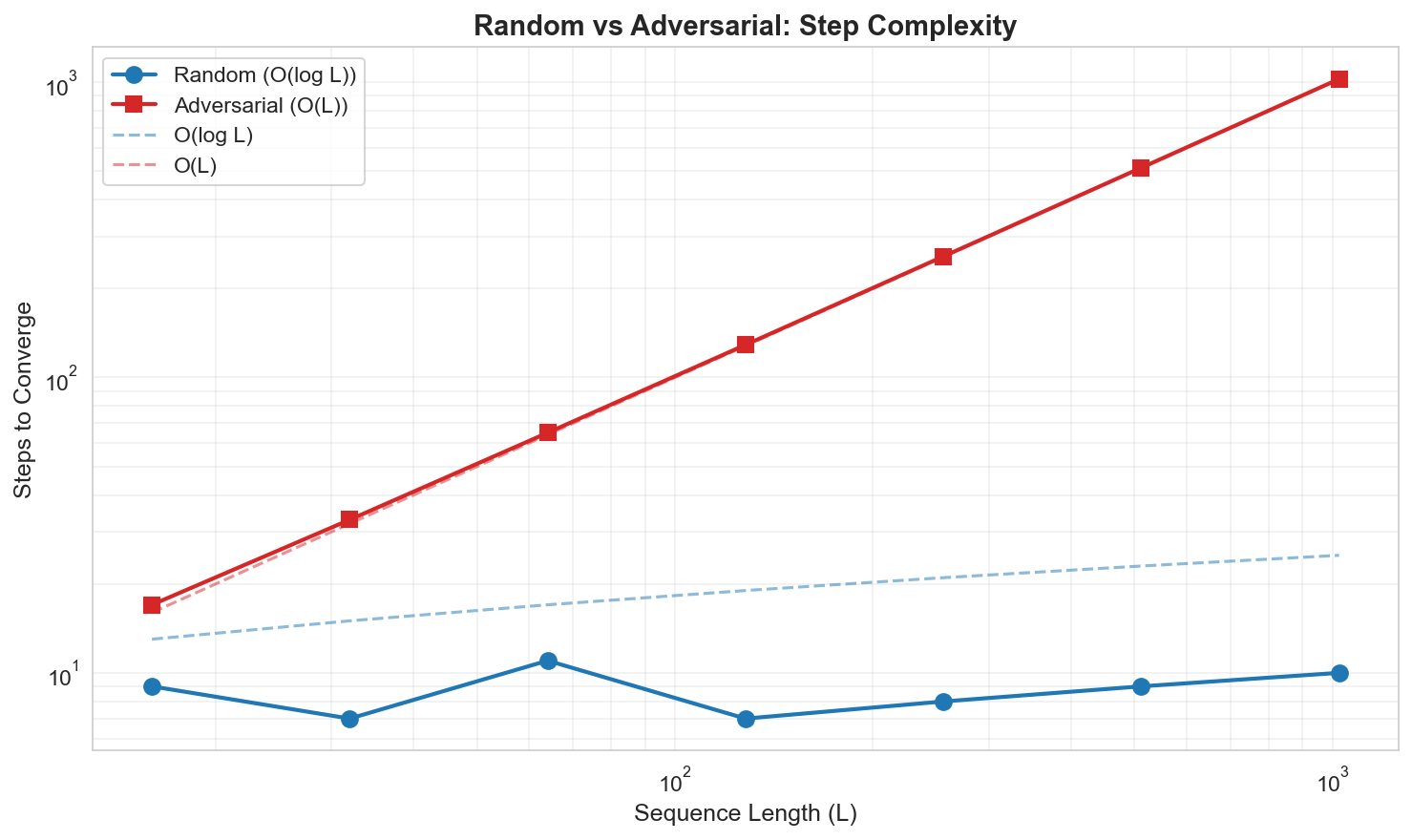
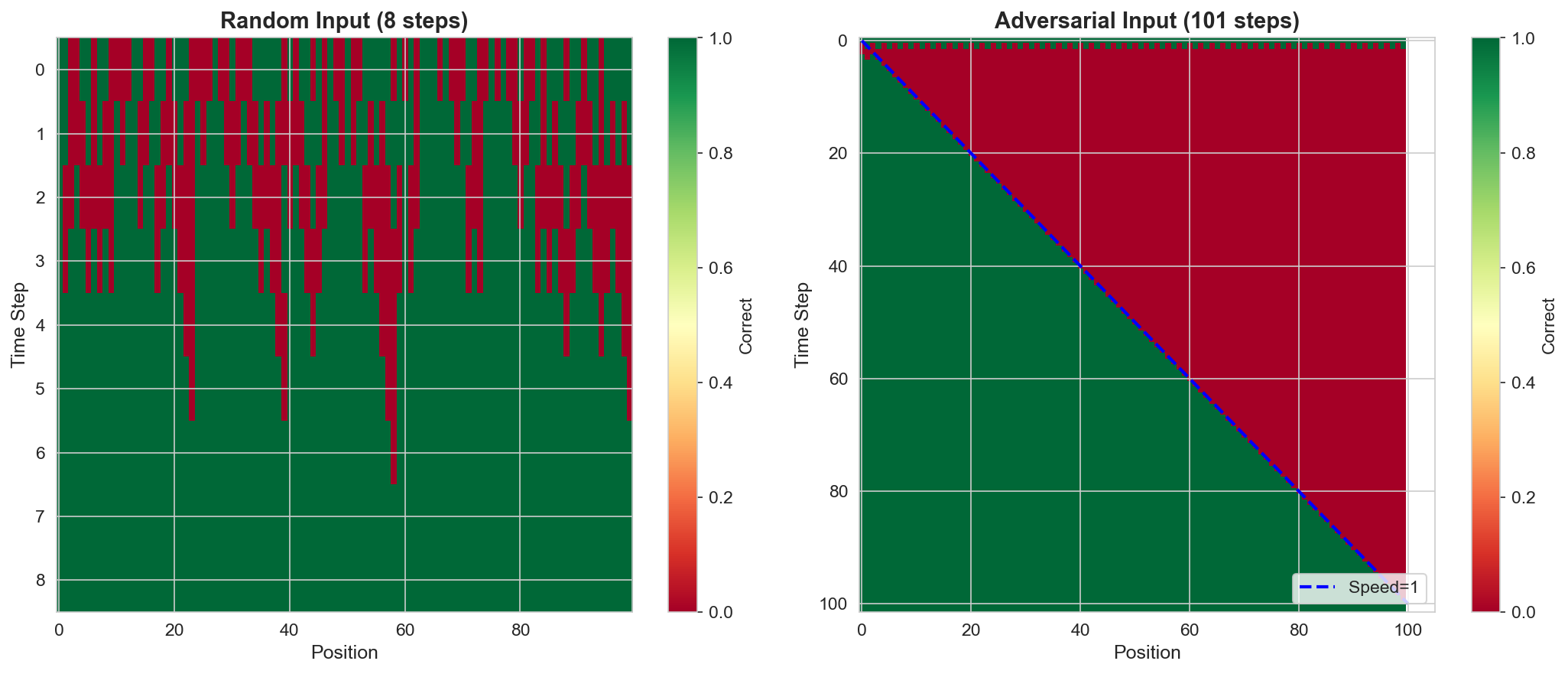
An informative comparison arises between random and adversarial inputs. Random additions rarely produce long carry chains, so the computation is locally bounded. Adversarial inputs (e.g., adding 999...9 + 1) force carries to propagate across the full sequence. SEAD handles both cases, but the internal dynamics differ visibly: adversarial inputs produce wave-like propagation patterns where the carry signal travels across the grid, while random inputs converge more uniformly.
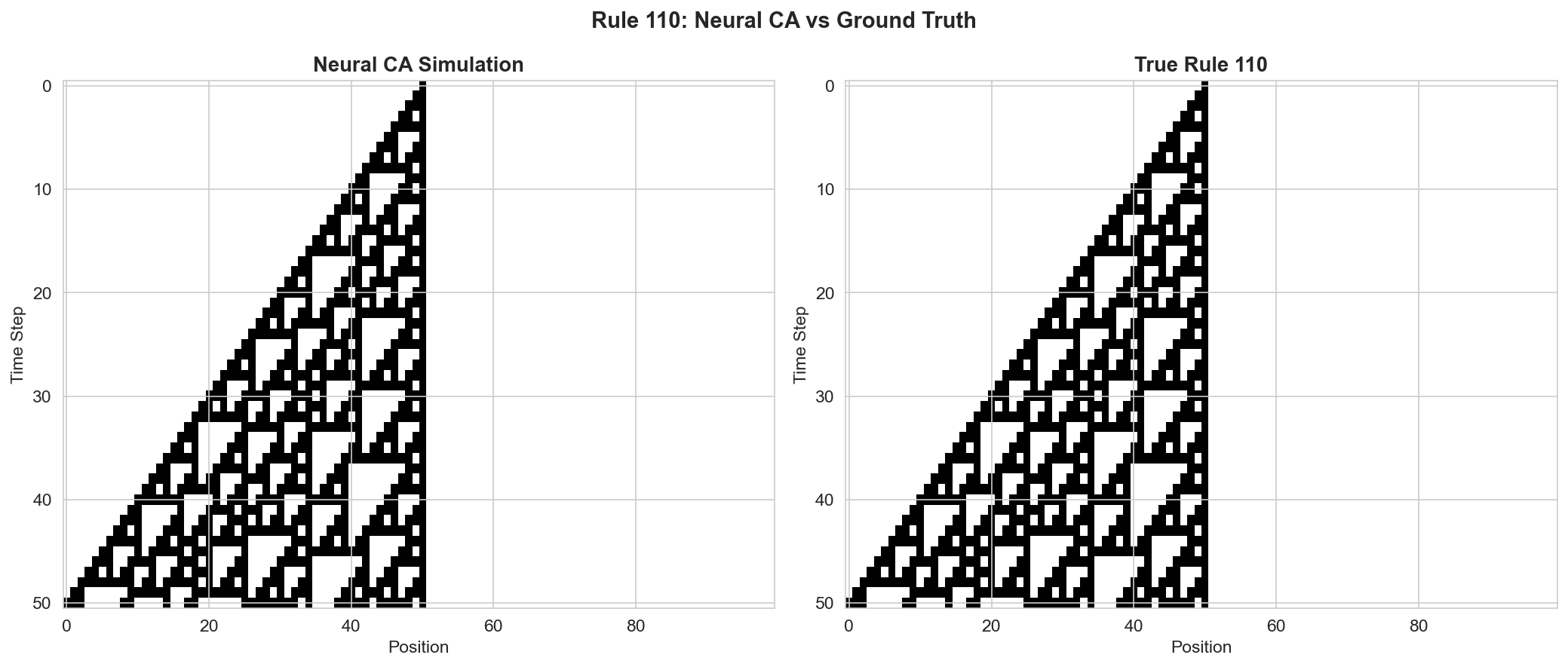
4.3 Rule 110
Rule 110 is an elementary cellular automaton proven to be Turing-complete, and widely studied in the theory of computation. Learning to simulate Rule 110 is therefore a test of whether SEAD can learn an arbitrary Turing-complete computation while maintaining stable dynamics.
SEAD successfully learns the Rule 110 update function. The dissipation mechanism (Postulate 3) is critical here: without it, an iterative system attempting to simulate a chaotic CA would diverge. The sigmoid activation bounds the dynamics, allowing the system to faithfully reproduce the target CA's behavior step by step without accumulating unbounded error.
5. Discussion
The three postulates are not arbitrary design choices. They are physical constraints that any spatially extended information-processing system must satisfy if it is to operate reliably at arbitrary scale. Locality ensures that the computational cost per cell is constant; symmetry ensures that what is learned at one position transfers to all others; dissipation ensures that the iterative computation terminates.
This perspective reframes length generalization not as a property to be engineered into a model, but as a consequence of respecting physical law. A Transformer violates Postulate 1 (its attention is global) and Postulate 2 (positional encodings break spatial symmetry). It is therefore not surprising, from this viewpoint, that Transformers struggle with length generalization — they are architecturally incapable of it in the same way that a faster-than-light signal is physically impossible.
The connection to Anderson's "More is Different" is deliberate. Anderson argued that the behavior of large systems cannot be understood by extrapolating from small ones; new organizational principles emerge at each scale. SEAD inverts this: by building in the right physical constraints from the start, behavior learned at small scale does transfer to large scale, because the constraints guarantee scale invariance.
Limitations. The postulates as stated apply most naturally to 1D sequence tasks with local dependencies. Tasks requiring genuinely global computation in a single step (such as sorting or certain graph problems) may need extensions to the framework. The relax-and-project mechanism, while flexible, means that inference time grows with input complexity — a tradeoff between generality and speed. The current experiments, while spanning a range of complexity, are limited to well-defined algorithmic tasks; the applicability to natural language remains an open question.
6. Conclusion
We have proposed three physics-inspired postulates — relativistic causality, spacetime symmetry, and dissipation — and shown that they jointly derive a neural cellular automaton architecture (SEAD) that achieves systematic length generalization. On parity, addition ($L = 16 \to L = 1{,}000{,}000$ at 100% accuracy), and Rule 110, SEAD demonstrates that length generalization is not an empirical trick but a structural consequence of respecting physical constraints on information processing.
The key insight is that generalization across scale is not something to be added to a model; it is something that emerges when the model's architecture is consistent with the physics of spatially extended computation. The three postulates provide a principled foundation — grounded in causality, symmetry, and stability — for understanding when and why neural networks can generalize beyond their training distribution.