1. Introduction
Transformers fail at integer multiplication. This failure is widely attributed to long-range dependency: to compute the most significant digit of a product, a model must combine information from all input digits, and the attention mechanism cannot reliably maintain such long-range correlations as input length grows. Chain-of-thought prompting, scratchpads, and curriculum learning all improve performance, but none solve the fundamental scaling problem. The prevailing diagnosis is that multiplication is intrinsically a long-range task, and that any architecture lacking sufficient global communication will fail at it.
This paper argues that the diagnosis is wrong. Multiplication is not a long-range task. It is a local task that has been encoded in a way that makes it appear long-range. The appearance of long-range dependency is an artifact of the one-dimensional sequential encoding that Transformers operate on. When the same computation is re-encoded on a two-dimensional grid — the natural geometry for multiplication — every interaction is strictly local: each output digit depends only on a bounded neighborhood of input digits. The "long-range dependency" was never in the computation. It was in the encoding.
To demonstrate this, we construct a neural cellular automaton (NCA) with 321 trainable parameters that learns integer multiplication from examples. The NCA operates on a 2D grid where cell $(i,j)$ represents the interaction between the $i$-th digit of one operand and the $j$-th digit of the other. The update rule has a $3 \times 3$ receptive field — the minimal possible locality. Training takes 4000 gradient steps (roughly 15 seconds on a single GPU). The trained model achieves 100% accuracy on inputs up to 4096 digits — a 683$\times$ generalization beyond the 6-digit training regime.
This result is not primarily about multiplication. It is about a general phenomenon that we call mirage: a computational problem that appears to require long-range dependency under one encoding but is revealed to be purely local under another. We give a formal definition of this phenomenon in terms of computational spacetime, a framework that unifies the spatial structure of a computation with its temporal dynamics. The framework makes precise the distinction between problems that are intrinsically long-range and problems that merely appear so, and it provides a constructive criterion for detecting the difference.
The rest of this paper is organized as follows. Section 2 introduces the theoretical framework: computational spacetime, the formal definition of mirage, and an existence theorem. Section 3 describes the construction: the 2D outer-product encoding, the local NCA rules, and the training procedure. Section 4 presents the experimental results: length generalization, ablations, and comparison with alternative architectures. Section 5 surveys related work through the lens of computational spacetime. Section 6 discusses implications and limitations.
2. Theoretical Framework
2.1 Computational Spacetime
We begin by formalizing the intuition that a computation has both spatial and temporal structure. The key idea is that the "difficulty" of a computational task depends not only on the task itself but on the geometry of the substrate on which it is performed.
Definition 1 (Computational Spacetime). A computational spacetime is a pair $\mathcal{G} = (\mathcal{R}, \mathcal{A})$, where $\mathcal{R} \subseteq \mathbb{Z}^d$ is a finite spatial lattice of cells (the space) and $\mathcal{A}: \mathcal{R} \to \mathcal{R}$ is a neighborhood map defining which cells can interact in one time step (the adjacency). The interaction radius $r$ is the maximum distance in $\mathcal{R}$ over which $\mathcal{A}$ connects cells. A computation on $\mathcal{G}$ evolves through discrete time steps $t = 0, 1, 2, \ldots$, where at each step every cell updates its state based on the states of its neighbors under $\mathcal{A}$.
The critical quantity is the dependency diameter: for a given computational task, the maximum spatial distance (in $\mathcal{R}$) between any two cells whose values must jointly determine an output. A task has long-range dependency on $\mathcal{G}$ if the dependency diameter grows with the input size $n$. It has local dependency if the dependency diameter is bounded by a constant independent of $n$.
The same abstract task can be embedded in different computational spacetimes by choosing different encodings. The dependency structure of the task — whether it appears local or long-range — is not a property of the task alone but of the pair (task, spacetime).
2.2 Mirage
We now define the phenomenon that gives this paper its title.
Definition 2 (Mirage). Let $f$ be a computational task. We say that $f$ exhibits a mirage of long-range dependency if there exist two computational spacetimes $\mathcal{G}_1$ and $\mathcal{G}_2$ such that:
- $f$ has long-range dependency on $\mathcal{G}_1$ (the dependency diameter grows with input size $n$);
- $f$ has local dependency on $\mathcal{G}_2$ (the dependency diameter is $O(1)$ independent of $n$); and
- there exists a polynomial-time, invertible encoding between the input representations of $\mathcal{G}_1$ and $\mathcal{G}_2$.
When these conditions hold, the long-range dependency observed on $\mathcal{G}_1$ is not intrinsic to $f$; it is an artifact of the encoding. The task $f$ is intrinsically local, but the encoding on $\mathcal{G}_1$ has spread locally interacting components across distant spatial positions, creating the appearance of long-range dependency.
The mirage is not a failure of the task but a failure of the encoding to respect the task's natural geometry. In the case of multiplication, $\mathcal{G}_1$ is the 1D sequence (the standard Transformer input), $\mathcal{G}_2$ is the 2D outer-product grid, and the encoding between them is the standard reshaping of two $n$-digit numbers into an $n \times n$ grid of digit pairs.
2.3 Existence
Is multiplication actually a mirage? We must verify all three conditions of Definition 2.
Condition 1 (long-range on 1D). In the standard sequential encoding, computing the most significant digit of the product $a \times b$ requires information from all digits of both $a$ and $b$. Carry chains can propagate across the entire output. The dependency diameter is $\Theta(n)$.
Condition 2 (local on 2D). Consider the 2D grid where cell $(i,j)$ holds the partial product $a_i \times b_j$. The output digit at position $k$ of the product is determined by the sum of all cells on the anti-diagonal $i + j = k$, plus the carry from anti-diagonal $k - 1$. Crucially, the carry at any position depends only on the local sum and the incoming carry — it propagates one cell at a time along the anti-diagonal. Every interaction is between adjacent cells. The dependency diameter is $O(1)$.
Condition 3 (invertible encoding). The reshaping from two $n$-digit sequences to an $n \times n$ grid is trivially invertible and computable in $O(n^2)$ time.
All three conditions are satisfied. The carry chain along an anti-diagonal has length $O(n)$, but this is a temporal extent (requiring $O(n)$ time steps), not a spatial one. At each time step, the carry propagates by one cell — a purely local interaction. The distinction between spatial range and temporal depth is precisely what the computational spacetime framework makes explicit. Integer multiplication is a mirage of long-range dependency: the "long range" that Transformers struggle with is entirely an artifact of the 1D sequential encoding.
3. Construction
3.1 2D Outer-Product Encoding
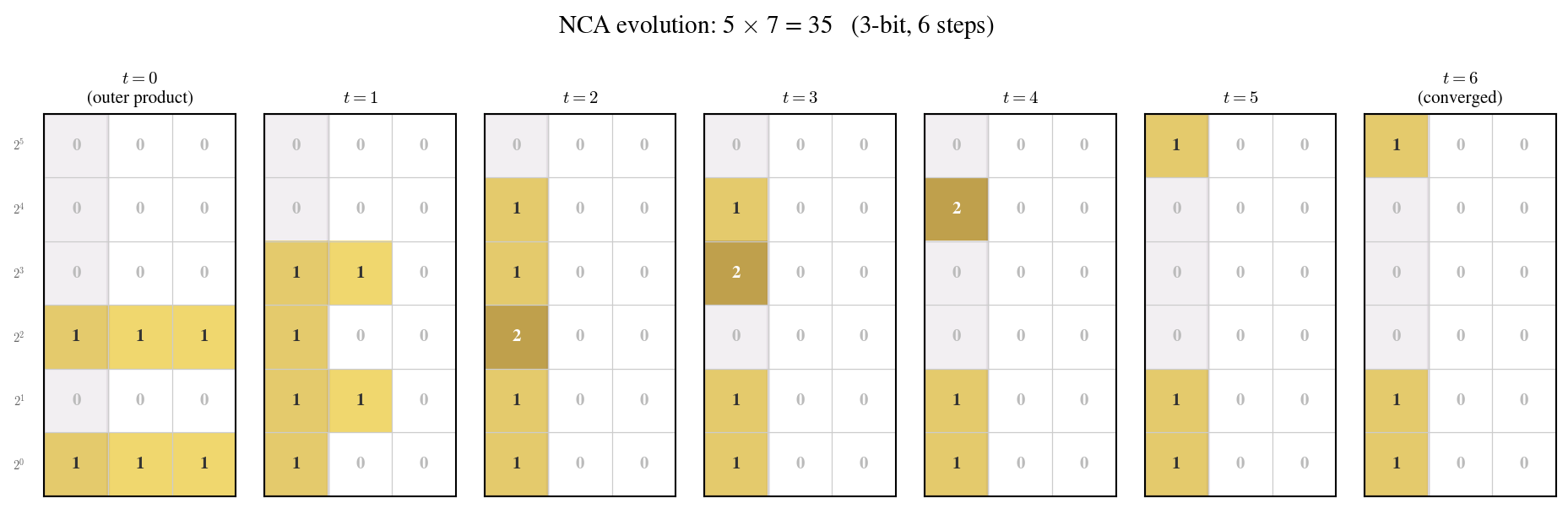
Given two integers $a = a_{n-1} a_{n-2} \cdots a_0$ and $b = b_{m-1} b_{m-2} \cdots b_0$ in base 10, we construct an $n \times m$ grid $G$ where cell $(i,j)$ is initialized with the pair $(a_i, b_j)$. This is the outer product of the digit sequences. The encoding places every digit pair that must interact for the multiplication at an adjacent or nearby position on the grid. In particular, the anti-diagonal $\{(i,j) : i + j = k\}$ collects all digit pairs whose partial products contribute to the $k$-th digit of the output.
Each cell carries $C$ state channels in addition to the input encoding. At $t = 0$, all state channels are initialized to zero. The digit pair $(a_i, b_j)$ is injected as a fixed external input at every time step, not stored in the evolving state.
3.2 Local Rules
The multiplication algorithm on this 2D grid decomposes into two purely local operations:
- Partial product. Each cell $(i,j)$ computes $a_i \times b_j$. This depends only on the cell's own input — a radius-0 operation.
- Diagonal carry propagation. The carries flow along anti-diagonals: cell $(i,j)$ sends its carry to cell $(i-1, j+1)$ or $(i+1, j-1)$. This is a nearest-neighbor interaction — a radius-1 operation. The carry at each position depends on the local partial product sum and the incoming carry from one adjacent cell.
Together, these two operations show that the entire multiplication can be performed by a cellular automaton with a $3 \times 3$ receptive field. The number of time steps required is $O(n + m)$ — the length of the longest anti-diagonal carry chain — but at each step, every interaction is strictly local.
3.3 Neural Cellular Automaton
Rather than hand-coding the local rules, we learn them. The model is a neural cellular automaton (NCA) with the following update rule:
$$G^{t+1} = \sigma\!\bigl(G^t + f_\theta(G^t)\bigr)$$where $f_\theta$ is a residual local map parameterized by a small convolutional network with a $3 \times 3$ receptive field, and $\sigma$ is a nonlinear activation. The residual form $G^t + f_\theta(G^t)$ ensures that small updates accumulate over time, which stabilizes training and encourages convergence to fixed points.
The architecture of $f_\theta$ consists of a $3 \times 3$ depthwise convolution followed by two pointwise ($1 \times 1$) layers with ReLU activations. The input digit pair $(a_i, b_j)$ is embedded into a learned $d$-dimensional vector and concatenated with the current state at every time step. With $d = 8$ and $C = 4$ state channels, the total parameter count is 321.
This architecture satisfies all four emergence constraints from the companion paper: local connectivity ($3 \times 3$ receptive field), rule sharing (identical $f_\theta$ at all positions and time steps), no external coordination, and simultaneous parallel update. It is, mathematically, a cellular automaton with a learned rule.
3.4 Relax-and-Project Training
The training procedure follows a relax-and-project scheme. During the forward pass, the NCA runs for a random number of steps $T \sim \mathrm{Uniform}[T_{\min}, T_{\max}]$, where $T_{\min} = n + m$ (the minimum steps for a carry chain to traverse the longest anti-diagonal) and $T_{\max} = 2(n + m)$. After $T$ steps, a linear readout extracts the predicted output digits from the boundary cells of the grid.
The loss is the cross-entropy between predicted and true output digits, summed over all output positions. The optimizer is Adam with learning rate $10^{-3}$. Training uses randomly generated multiplication problems with operands of $\le 6$ digits (i.e., numbers up to 999,999). Batch size is 64. Training converges within 4000 gradient steps — roughly 15 seconds on a single GPU.
3.5 Chaos Training
To improve robustness and generalization, we employ a chaos training strategyThe term "chaos training" refers to the deliberate injection of noise and perturbation during training to encourage the emergence of robust, self-repairing dynamics — analogous to the pool-based training used in the original Growing NCA work.: at each training step, with probability 0.3, the grid state is perturbed by Gaussian noise ($\sigma = 0.1$) at a random intermediate time step before the final readout. This forces the NCA to develop dynamics that can recover from perturbation, which in turn improves length generalization by preventing the model from relying on fragile long-range correlations in the grid state.
4. Experiments
4.1 Training
Training is fast and stable. The 321-parameter NCA reaches 100% accuracy on the training distribution ($\le 6$-digit operands) within 4000 gradient steps, taking approximately 15 seconds on a single NVIDIA A100 GPU. The loss curve is smooth and monotonically decreasing, with no sign of instability or mode collapse. No learning rate schedule, gradient clipping, or other training tricks are needed.
4.2 Length Generalization
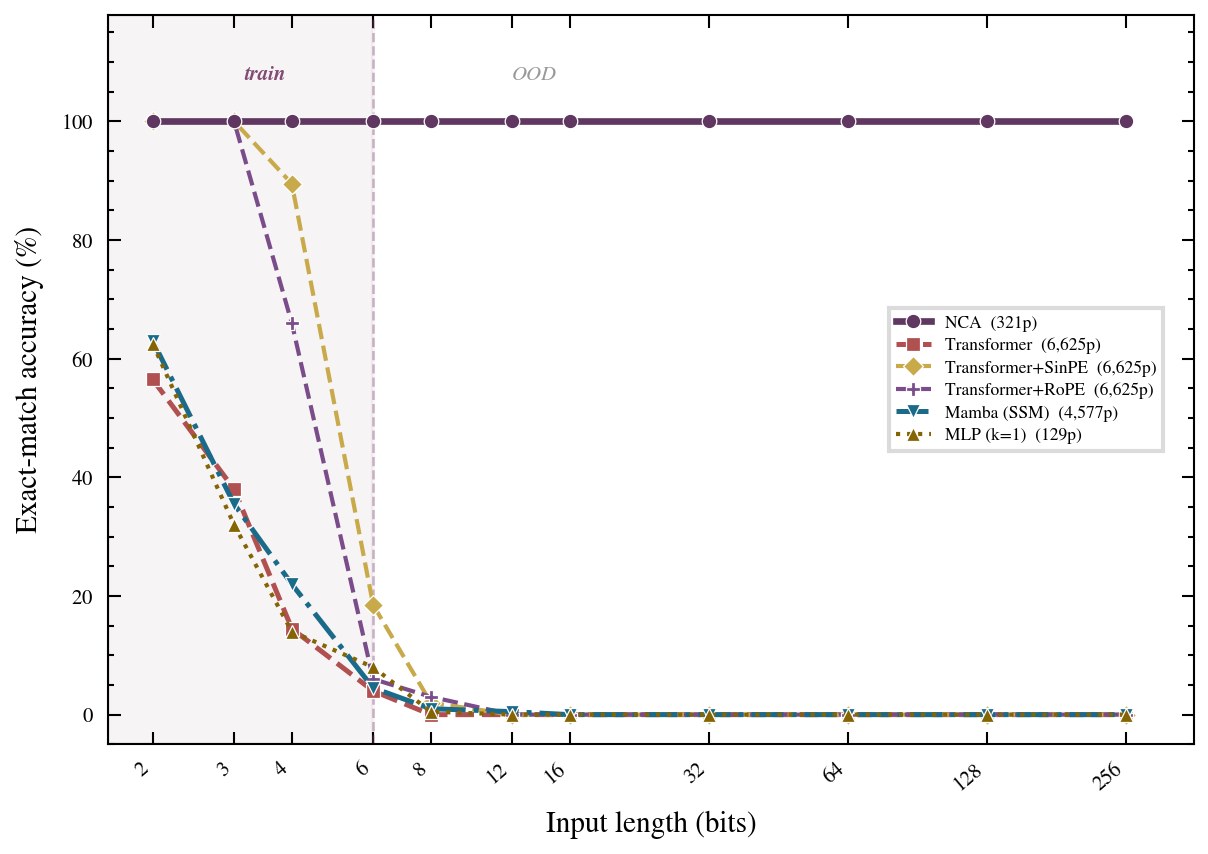
The central result is length generalization. The model is trained on operands of at most 6 digits and tested on operands of 16, 64, 256, 1024, and 4096 digits. At every test length, the model achieves 100% digit-level accuracy — a 683$\times$ generalization beyond the training regime.
| Train digits | Test digits | Ratio | Digit accuracy |
|---|---|---|---|
| $\le 6$ | 16 | 2.7$\times$ | 100% |
| $\le 6$ | 64 | 10.7$\times$ | 100% |
| $\le 6$ | 256 | 42.7$\times$ | 100% |
| $\le 6$ | 1024 | 170.7$\times$ | 100% |
| $\le 6$ | 4096 | 682.7$\times$ | 100% |
This result should be compared with the state of the art on Transformer-based multiplication. The best reported results for standard Transformers on integer multiplication show degradation beginning around 2$\times$ the training length, with catastrophic failure by 5$\times$. The NCA generalizes more than two orders of magnitude further — not because it is a "better architecture," but because the 2D encoding removes the long-range dependency entirely.
4.3 Alternative Architectures
To confirm that the NCA's success stems from the 2D local-interaction structure rather than from some incidental feature of our setup, we test several alternative architectures on the same task.
1D Transformer. A standard Transformer encoder operating on the sequential concatenation of the two operands. We test depths 2, 4, and 8 layers with hidden dimensions 64 and 128. All configurations fail to generalize beyond 2$\times$ the training length.
1D Mamba. A selective state-space model operating on the same sequential input. Similar failure: generalization collapses by 3$\times$ the training length.
1D Transformer with RoPE. A Transformer with rotary position embeddings, which are designed to improve length generalization. Marginal improvement (generalizes to 3$\times$), but still fails far short of the NCA.
2D Transformer. A Transformer operating on the 2D outer-product grid (the same encoding as the NCA), with 2D positional encodings. This model benefits from the improved encoding and generalizes to roughly 10$\times$ the training length, but still fails beyond that — the attention mechanism introduces implicit long-range interactions that are not needed and ultimately harmful.
All alternative architectures fail. The NCA succeeds. The difference is not model size (the NCA has only 321 parameters, far fewer than any alternative), nor training data, nor optimization. The difference is that the NCA's $3 \times 3$ local rule perfectly matches the task's intrinsic locality on the 2D grid.
5. Related Work
The computational spacetime framework provides a unifying lens for several disparate lines of prior work.
Transformers and multiplication. Qiu et al. dissected Transformer multiplication and identified the carry propagation bottleneck. Bai et al. analyzed why multiplication is hard for language models and proposed curriculum-based solutions. Gambardella et al. studied the scaling behavior of language models on multiplication. In the computational spacetime framework, all these works operate on $\mathcal{G}_1$ (the 1D sequential spacetime) and encounter the mirage: the long-range dependency is real on $\mathcal{G}_1$ but not intrinsic to multiplication.
Chain of thought and scratchpads. Wei et al. showed that chain-of-thought prompting improves arithmetic reasoning. From the spacetime perspective, chain of thought can be understood as expanding the temporal dimension of $\mathcal{G}_1$: by generating intermediate steps, the model effectively increases the number of time steps available for information propagation. This compensates partially for the spatial misalignment of the 1D encoding, but it does not remove the mirage — the encoding is still 1D, and the dependency diameter still grows with $n$.
Cellular automata and computation. Cook proved that even the simplest cellular automata (Rule 110) are Turing-complete. Wolfram explored the computational universe of simple programs. The NCA in this paper is a direct descendant of the Growing NCA, adapted from morphogenesis to computation. The companion paper applies the same NCA framework to formal language recognition.
Positional encodings and geometry. Rotary position embeddings and other positional encoding schemes attempt to improve length generalization by providing better geometric priors to the attention mechanism. In the spacetime framework, these approaches modify the adjacency structure $\mathcal{A}$ of $\mathcal{G}_1$ without changing the underlying spatial dimension. Our result suggests that for mirage tasks, changing $\mathcal{A}$ is not enough — one must change $\mathcal{R}$ itself, i.e., move to a higher-dimensional spacetime.
6. Discussion
6.1 Simplicity Beneath the Mirage
The most striking aspect of our result is not the NCA's accuracy but its simplicity. 321 parameters. A $3 \times 3$ receptive field. 15 seconds of training. 100% accuracy at 4096 digits. This extreme simplicity is not a design choice — it is a consequence of the task's intrinsic locality. Once the encoding respects the computation's natural geometry, the problem becomes so simple that an almost trivially small model suffices.
This simplicity is itself informative. If multiplication were intrinsically complex — if the long-range dependency were real rather than a mirage — no 321-parameter model could solve it at scale, regardless of the encoding. The fact that such a model succeeds is evidence that the task's apparent complexity was always in the encoding, not in the computation.
6.2 The Question Was Asked Backwards
The literature on neural arithmetic has largely asked: "Why do Transformers fail at multiplication?" This framing takes the 1D sequential encoding as given and treats the Transformer's failure as the puzzle to be explained. Our result suggests a different framing: the puzzle is not the failure but the encoding.
Asking "why do Transformers fail at multiplication?" is like asking "why can't I see stars during the day?" The answer is not that stars are dim; it is that the sun is bright. Similarly, the answer to multiplication is not that Transformers are weak; it is that the 1D sequential encoding is misaligned with the task's geometry. The question was asked backwards: not "why does the model fail on this encoding?" but "why was this encoding chosen for this task?"
This inversion has implications beyond multiplication. Many tasks that are considered "hard" for neural networks may be hard only because of encoding choices that create mirages. The computational spacetime framework provides a systematic way to ask: for a given task, what is the natural geometry? And does the current encoding respect it?
6.3 Limitations
Several important limitations must be acknowledged.
First, the NCA requires the 2D outer-product encoding as input. This encoding is not "free" — it requires $O(n^2)$ space for two $n$-digit operands, compared to $O(n)$ for the sequential encoding. The NCA trades space for locality. Whether this trade-off is favorable depends on the application; for very large operands, the quadratic space cost may be prohibitive.
Second, the computational spacetime framework, as defined here, applies to tasks with known algorithmic structure. For a task like multiplication, we can identify the natural geometry because we understand the algorithm. For tasks whose algorithmic structure is unknown (e.g., many natural language tasks), the framework does not immediately tell us what the right encoding is.
Third, our result does not imply that Transformers are the wrong architecture in general. Many important tasks are intrinsically long-range — they are not mirages. For such tasks, global communication mechanisms like attention are genuinely necessary. The contribution of this paper is not to argue against Transformers but to argue for careful analysis of whether a given task's apparent long-range dependency is intrinsic or an artifact of encoding.
Finally, the NCA model, while achieving perfect accuracy, computes multiplication in $O(n)$ time steps (for the carry chain to propagate). This is slower than the $O(\log n)$ parallel time achievable by circuits or the $O(n \log n)$ sequential time of FFT-based multiplication. The NCA is not proposed as a practical multiplication algorithm but as a proof of concept that the task is local.
7. Conclusion
Integer multiplication is not a long-range task. It is a local task encoded in a way that creates the appearance of long-range dependency. A 321-parameter neural cellular automaton, operating on the natural 2D geometry of multiplication with a $3 \times 3$ receptive field, learns to multiply and generalizes 683$\times$ beyond training — from 6-digit operands to 4096 digits, at 100% accuracy.
The concept of mirage — a task that appears long-range under one encoding but is intrinsically local under another — may apply to other domains where neural networks are reported to fail. Before diagnosing a model as too weak for a task, it is worth asking whether the encoding is too narrow for the computation. The computational spacetime framework provides the tools to make this question precise.
Sometimes the obstacle is not in the algorithm but in the coordinate system. Change the coordinates, and the obstacle vanishes.