1. Introduction
Neural language models produce syntactically well-formed language. This is an empirical fact. But when we open these systems up, we do not find explicit structures isomorphic to the syntactic objects familiar from classical linguistics: non-terminals, derivation rules, and discrete parse trees do not appear in that form inside the weights and states. Yet the outputs remain, to a substantial degree, syntactically legal.
LLMs let us see that this is possible, but they do not tell us how it happens. Their sheer scale is itself an obstacle: they are too large for us to locate a precise site at which "structured processing appears." Existing internal probes often carry enough computational capacity of their own that the "structure" they discover may reflect the probe's power rather than the model's representation. They cannot directly answer the question we want to ask. Let us therefore step back and pose the same question to a system simple enough to be observed in full: can a small, directly inspectable system also, on its own, handle a language that requires hierarchical structure? We do not treat it as a model of LLMs; we treat it only as an independent instance of the same phenomenon.
The strategy of this paper is to bypass natural language and start from a formal language with a precise mathematical description: an arithmetic-expression grammar. This grammar comes with a fully determined reference point: the CKY algorithm gives a zero-error parse for it. Against this reference point we construct a minimal system: an 18,658-parameter two-dimensional neural cellular automaton, supervised only by a 1-bit boundary signal that spans the entire sequence.
What we observe is the spontaneous emergence of internal structure. The $L \times L$ grid self-organizes into an ordered, spatially extended representation. It satisfies the three operational criteria for syntactic processing that we state in the next section. It is quantitatively correlated with the CKY chart (Pearson $r \approx 0.71$), but it is not a copy of CKY: its states are continuous, it regenerates spontaneously after perturbation. It emerges independently on four distinct context-free grammars. We name this structure Proto-CKY.
This empirical observation is itself worth opening up. The body of the paper first defines the criteria (§2), then reports the observations and rules out alternative explanations one by one (§3–5). But all of this is groundwork. The real question comes at the end: what, exactly, is the relation between the thing we have observed and the mathematical object it seems to point to?
2. Background
The title of this paper promises "the emergence of syntax." Any careful reader will note that both words carry different meanings in different disciplinary traditions, and that in the overlapping public discourse these meanings are routinely conflated without scrutiny. Unless we give each concept an operational criterion that does not presuppose its conclusion, we are either forcing an ill-fitting label onto something or rigging the alignment.
2.1 Syntactic Processing
If syntactic processing can emerge from a physical system, the emergent structure will almost certainly not be the kind of symbolic object that formal language theory takes as primitive. It will not be non-terminals, derivation rules, or discrete parse trees. To judge whether such a structure counts as "syntactic processing," we need a definition that does not presuppose symbolic form; otherwise we have already excluded every non-symbolic answer.
We adopt a behavioral working definition. It does not adjudicate the traditional disputes between formalist and functionalist approaches, between constituency and dependency; its commitments are only to observable behavior and inspectable internal organization. Concretely, we say that a system exhibits syntactic processing if it satisfies all three of the following:
- Expressive power beyond the regular languages. The system correctly handles at least one class of phenomena expressible only by a CFG (such as bracket matching or operator precedence), and its behavioral boundary clearly exceeds what any finite-state machine can reach.
- Structural productivity. On inputs outside the training distribution, whether legal or illegal, the system exhibits systematic, structured response patterns rather than arbitrary or surface-statistics-driven ones. The spirit of this criterion traces back to Humboldt's classical observation about language as "the infinite use of finite means": a finite set of rules capable of producing infinitely many legal structures. This criterion rules out lookup tables and shallow template matching.
- Syntactically relevant internal organization. The internal states of the system spontaneously form an organization quantitatively aligned with grammatical structure. This criterion rules out black boxes that happen to produce correct outputs but have no internal structure, as well as systems that have internal organization unrelated to grammar.
A note on these three. We deliberately do not require perfect classification on all legal and illegal inputs. Consider an obvious example: humans. No one would deny that humans command syntax, yet humans are fooled by garden-path sentences, break down on center-embedding at depth $\ge 3$, and disagree with one another on marginal grammaticality judgments. That a physical system handling hierarchical structure exhibits boundary quirks of this kind does not mean it lacks syntactic processing. The three criteria demand structured productivity aligned with grammar, not zero error.
The first two criteria are behavioral: they specify what input-output relations count as "getting it right." The third is representational: it requires that getting it right passes through some internal organization. Together the three constitute a falsifiable working definition.
2.2 Emergence
"Emergence" has a popular usage in the contemporary machine-learning literature: a model, upon scaling up, suddenly displays capabilities not explicitly taught during training. Under this usage, emergence is an empirical phenomenon about scale, making no commitment about the internal mechanisms that produce it.
This notion of emergence is not itself beyond question. Schaeffer et al. showed that the supposed capability jumps may be measurement artifacts created by nonlinear evaluation metrics: switch the metric, and the jump vanishes. An "emergence" that can appear or disappear depending on the choice of yardstick is not a reliable scientific concept.
This paper takes emergence in its original sense: many simple components interacting under local rules, without external coordination, spontaneously produce ordered structure at the global level. Emergence is not "unexpectedly getting it right"; it is "global order growing spontaneously from local interaction."
To sharpen this intuition into testable constraints, we say that a global property of a system satisfies the emergence constraints if the process that produces it meets all four of the following:
- Local connectivity. The state at any position depends only on a fixed-size neighborhood, independent of the overall system size.
- Rule sharing. All positions use the same update rule, independent of coordinates.
- No external coordination. There is no external algorithm that decides the update order, and no global synchronization across neighborhoods.
- Simultaneous evolution. All positions update in parallel at the same discrete time step; time is homogeneous.
Together the four characterize a centerless process: no global scheduler, no privileged position, no direct communication across neighborhoods. Any global order, if it appears, can only grow spontaneously from the iteration of local rules.
As a contrast, consider the existing approaches to syntactic processing. Whether classical parsing algorithms (CKY, the Earley parser, shift-reduce) or neural mechanisms (attention), they all rely on some form of global coordination. Take CKY as an example: it fills a two-dimensional chart bottom-up, with each cell $(i,j)$ recording the set of non-terminals that can derive the substring $[i,j]$, yielding a zero-error answer. But the filling order is globally choreographed by span length; the chart itself has no dynamics. CKY is a designed solution, not an emergent one. In this paper it serves as a reference point: a known mathematical object with sharp symbolic meaning, against which we compare the emergent internal structure.
A system satisfying all four constraints is, mathematically, a cellular automaton (CA). This paper uses its neural variant, the neural cellular automaton (NCA), whose architecture is described in the next section. It is worth pointing out that the emergence constraints are stronger than "convolutional neural network": a deep convolutional network has a fixed number of layers that implicitly prescribes the rounds of information propagation. The emergence constraints require a single local rule applied repeatedly until convergence, with no architectural partitioning into rounds.
The experimental question of this paper can now be stated precisely: on a system satisfying the emergence constraints, can ordered structure arise spontaneously to perform syntactic processing that satisfies all three criteria?
2.3 Relation to Prior Work
This question connects to three existing lines of research.
The first is linguistic structure inside neural networks. That neural networks implicitly acquire representations correlated with linguistic structure is an observation with a clear lineage. Manning et al. surveyed the evidence that self-supervised training yields language-like structure inside ANNs; Lake and Baroni tightened the pressure test on compositional generalization; McCoy et al. warned that "getting it right" does not always mean "getting it right for the right reasons." We share the source of this question while shrinking it to a scale at which the inside can be directly inspected.
The second is the expressive power of neural networks on formal languages: which classes of language RNNs and Transformers can recognize, how much memory they require, and where the boundary of Turing completeness lies. For the cellular automaton used in this paper, the expressive-power question is trivial: CA has been proven Turing-complete and can in principle compute any computable function. But Turing completeness only answers "can it?", not "in what form?" This paper is concerned with the latter.
The third is neural cellular automata. Since Mordvintsev et al. first introduced them, NCAs have been applied to 3D construction, self-classification, control tasks, and attention-augmented variants. The present paper is the first application of NCAs to the membership problem on a formal language.
3. Experimental Setup
The experimental task must satisfy two conditions: it must genuinely require hierarchical analysis (otherwise the first criterion for syntactic processing cannot be tested), and it must be simple enough to control and interpret. We choose an arithmetic-expression grammar. It shares the core syntactic features of natural language (hierarchical constituent structure, recursive nesting) without the additional complexity introduced by semantic and pragmatic factors. Concretely, the membership problem is defined on the following grammar:
$$E \to E + T \mid T, \quad T \to T \times F \mid F, \quad F \to (E) \mid \text{id}$$Converted to Chomsky normal form this yields 5 tokens, 11 non-terminals, and 9 binary rules. Given a token sequence, the model decides whether it is a legal expression. The grammar has operator precedence and recursive nesting; its CKY chart is non-trivial.
The model is a 2D NCA defined on an $L \times L$ grid, with $C = 2$ state channels and 18,658 parameters. The grid is indexed by the matrix convention: cell $(i, j)$ lies in the $i$-th row (corresponding to the $i$-th token of the sequence) and the $j$-th column (corresponding to the $j$-th token). At $t = 0$ the grid is completely uniform (all zeros). The update rule is:
$$\mathbf{h}_{t+1}(i,j) = \sigma\!\bigl(W_h \cdot \mathrm{relu}(W_2 \cdot \mathrm{relu}(W_1 \cdot [\mathbf{e}_i;\, \mathbf{e}_j;\, W_s \mathbf{h}_t(i,j)]))\bigr)$$where $\mathbf{e}_i, \mathbf{e}_j \in \mathbb{R}^d$ are the learned embeddings of the $i$-th and $j$-th tokens ($d = 16$), $W_s$ projects the current state into the embedding space, $W_1, W_2$ are $3 \times 3$ convolution kernels, $W_h$ is a $1 \times 1$ output head, and $\sigma$ is the sigmoid. Token information is injected externally at every step; it is not stored on the grid.
This architecture satisfies the four emergence constraints stated above: the receptive field is a $3 \times 3$ neighborhood (local connectivity); $W_1, W_2, W_h$ are shared across all spatial positions and all time steps (rule sharing); no external algorithm decides the update order (no external coordination); all cells update in parallel at the same discrete step (simultaneous evolution). From the perspective of rule-execution dynamics, this is a standard cellular automaton; the only difference is that the rule is learned rather than hand-designed.
The supervision signal is only 1 bit: the upper-right cell $(0, L\!-\!1)$, the position that spans the entire sequence, has its channel 0 trained by BCE loss to predict sequence legality. The remaining $L^2 \times C - 1$ grid values receive no supervision whatsoever. Training data is generated on the fly (batch size 64), with sequence length $L \le 12$ and balanced positive and negative samples. For each training sample, the number of NCA iterations is sampled uniformly from $[3, \max(6, 2L)]$, forcing the model to produce correct predictions at varying iteration depths. The optimizer is Adam (learning rate $10^{-3}$); training converges within roughly 2000 gradient steps.
At test time the NCA iterates until convergence ($\max |\mathbf{h}_{t+1} - \mathbf{h}_t| < \epsilon = 0.01$), with a step cap of $\max(50, L)$. OOD evaluation uses a balanced protocol: at each test length, 100 legal flat expressions and 100 constructively illegal sequences.
To probe universality, we train the same architecture on five additional languages (varying only the training data): Dyck-1 (matched parentheses, 2 tokens), Dyck-2 (two kinds of parentheses, 4 tokens), NL Agreement (subject-verb agreement, 7 tokens), three context-free grammars, plus $a^*$ (all-$a$ sequences) and $a^* b^*$ ($a$'s followed by $b$'s), two regular languages serving as negative controls.
4. Experiments
4.1 The Emergence of Syntax
We have laid down three criteria for syntactic processing: expressive power beyond the regular languages, systematic productivity, and syntactically relevant internal organization. We have also established that our model is a system driven by local interaction alone. The question now is: can such a system satisfy all three at once?
Training converges within about 2000 steps. The converged model reaches 100% classification accuracy on the training distribution ($L \le 12$). The membership problem for arithmetic expressions genuinely requires the expressive power of a context-free grammar; in this sense, the first criterion is met.
The second criterion demands systematic productivity. If the model had merely memorized the statistical regularities of the training distribution, it should fail rapidly outside that distribution. In fact, on sequences far beyond the training length ($L = 50, 100, 500$, all the way to $L = 1000$, more than 80 times the training length), the model maintains 100% accuracy (Figure 1).
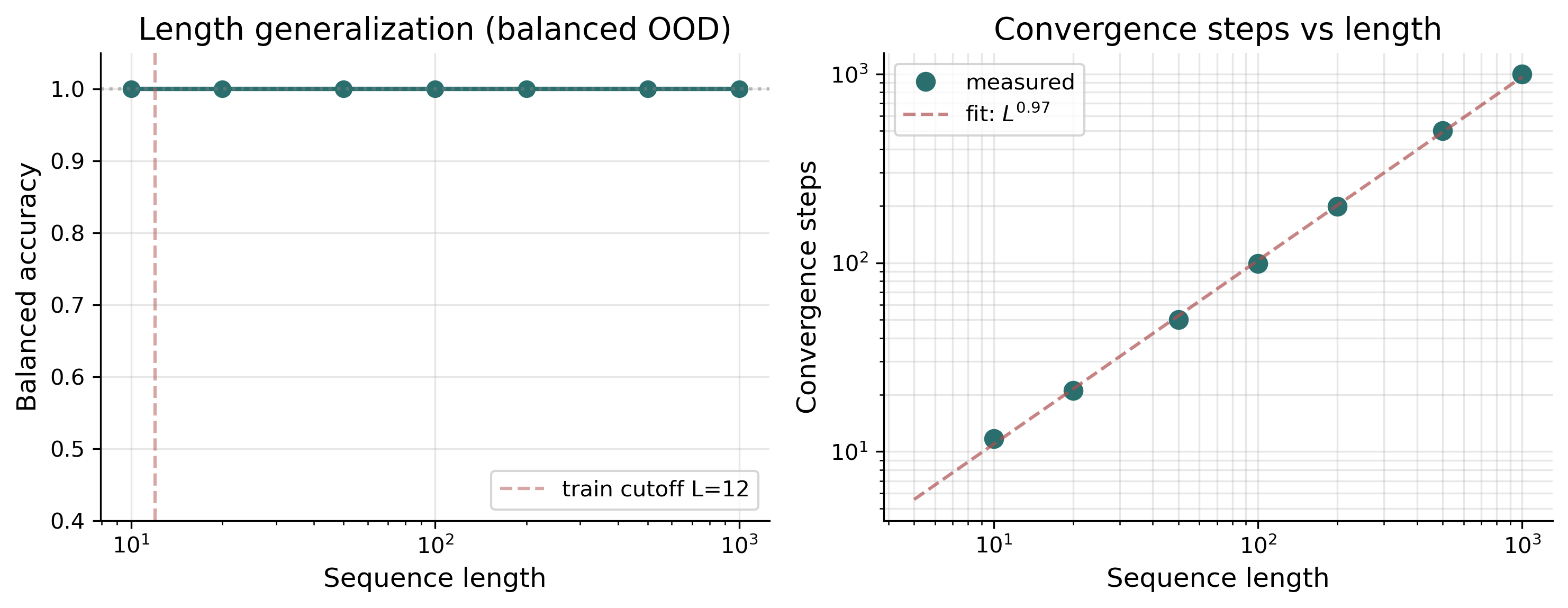
A detail worth explaining: training samples are generated on the fly within the window $L \le 12$, and in that window the overwhelming majority of randomly sampled legal expressions are flat. The main model therefore generalizes in the flat direction to very long sequences, but on purely nested inputs of depth $\ge 2$ it fails from the start. When we explicitly include depth 2–4 nested expressions at roughly 30% of training samples (deep augmentation), the same architecture generalizes to depth 10 on pure nested inputs and depth 7 on mixed depth-length inputs (Figure 2).
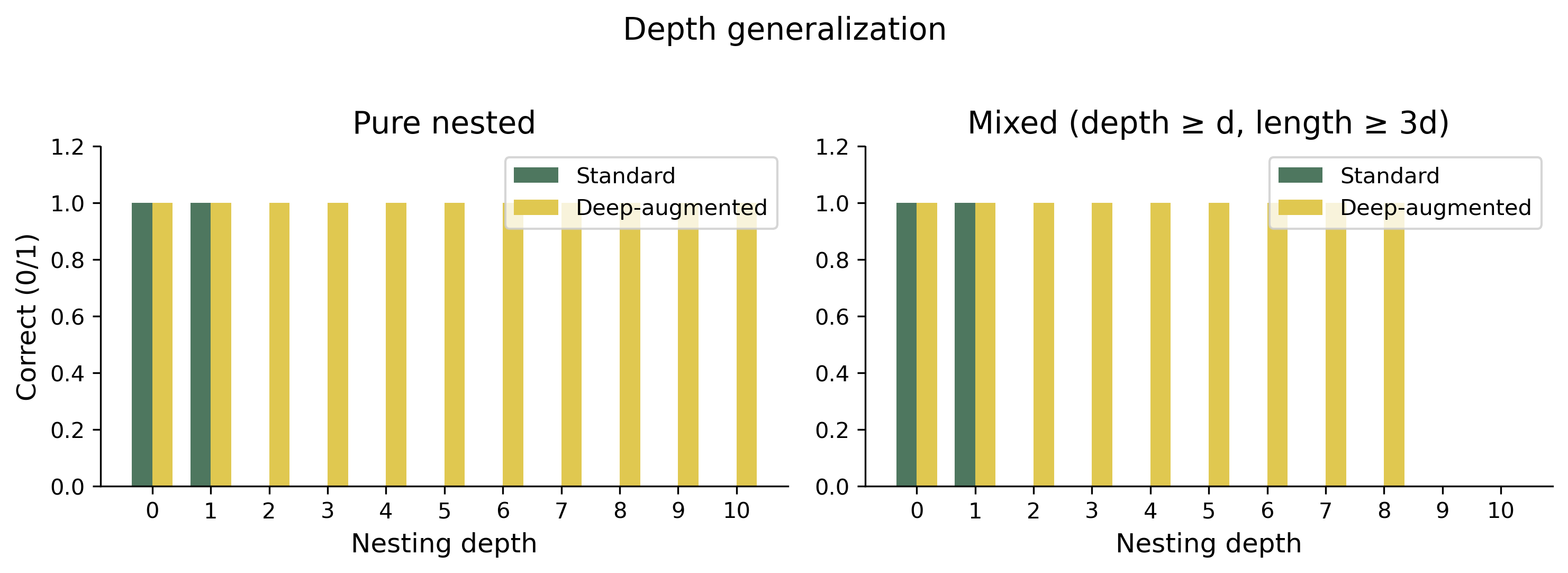
Regardless of which direction one looks, a structured mechanism operating stably outside the training distribution has emerged: past the boundary of any finite-state machine in the length direction, and into nesting structures never seen during training in the depth direction. The second criterion is met.
The third criterion is the most important, and the hardest. It requires that getting it right passes through some internal organization. An input-output black box, even if it satisfies the first two criteria, does not count as syntactic processing: the essence of syntax is processing of structure, not merely reacting to structured inputs. We must open the model up.
Before inference begins, the $L \times L$ grid is completely uniform: all cells are zero, carrying no information about the input, let alone any structure. After iterative relaxation, the grid self-organizes into a highly ordered activation pattern. This fact deserves emphasis: $L^2 \times C - 1$ grid values receive no supervision at all; their ordered organization is entirely spontaneous.
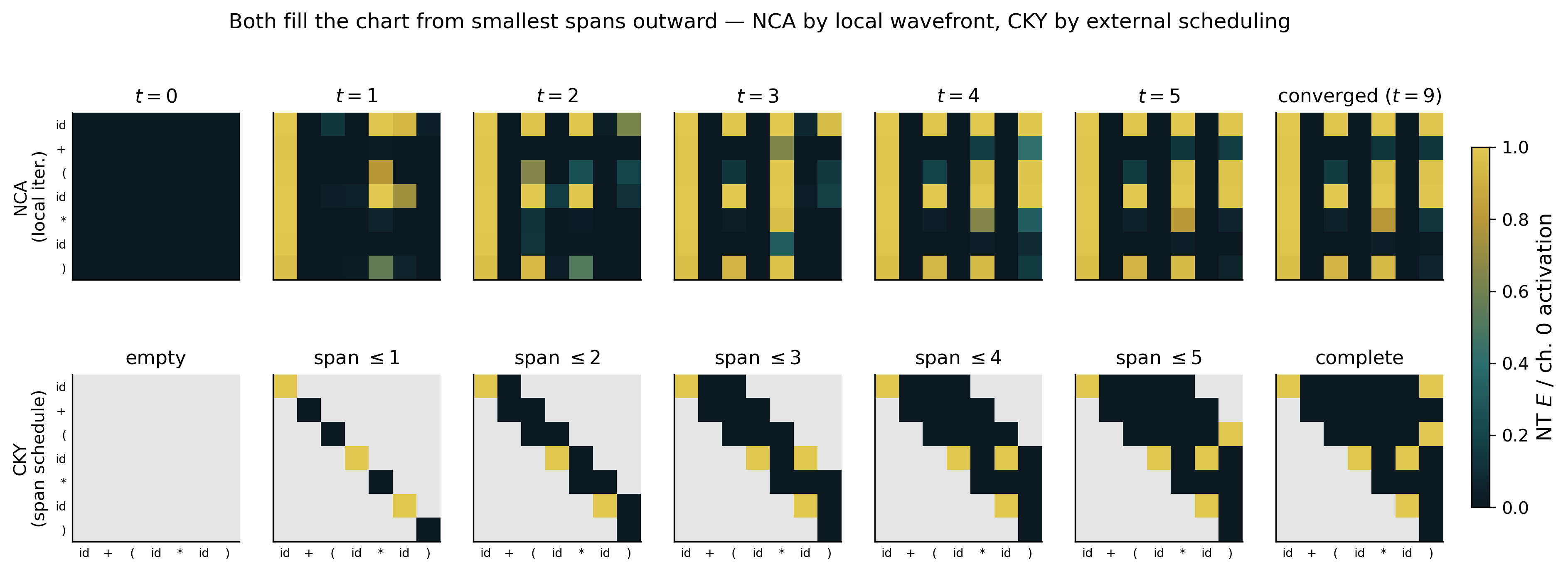
We name this ordered representation Proto-CKY (Figure 3). It shares a geometry with the CKY chart: both organize token pairs on a span lattice. But its internal mechanism differs substantially from CKY's. CKY fills the chart by discrete enumeration; Proto-CKY converges on the grid by continuous relaxation. CKY is choreographed by an external algorithm proceeding in order of span length; Proto-CKY is produced by a single local rule applied repeatedly until it reaches an attractor.
4.2 Proto-CKY Is Not Noise
A natural suspicion is that the ordered representation is merely a byproduct that any 2D NCA architecture would produce on any sequence-classification task. If so, it should appear indiscriminately across tasks, regardless of whether they involve hierarchical structure.
The most direct test is to find tasks that do not require syntax. We train the same architecture on two regular languages: $a^*$ (all-$a$ sequences) and $a^* b^*$ ($a$'s followed by $b$'s). Both models successfully learn their respective tasks, but both grids remain flat: the variance of the internal representation is $1.5 \times 10^{-3}$ and $4.6 \times 10^{-3}$, respectively, roughly two orders of magnitude below the $0.194$ measured on the arithmetic grammar. The ordered representation is not a default behavior of NCAs on arbitrary tasks.
Conversely, if the ordered representation is related to syntax, it should recur across different syntactic tasks. We train the same architecture separately on three other context-free grammars — Dyck-1, Dyck-2, and NL Agreement — varying only the training data and no part of the architecture. All four grammars independently produce ordered representations (Figure 4).
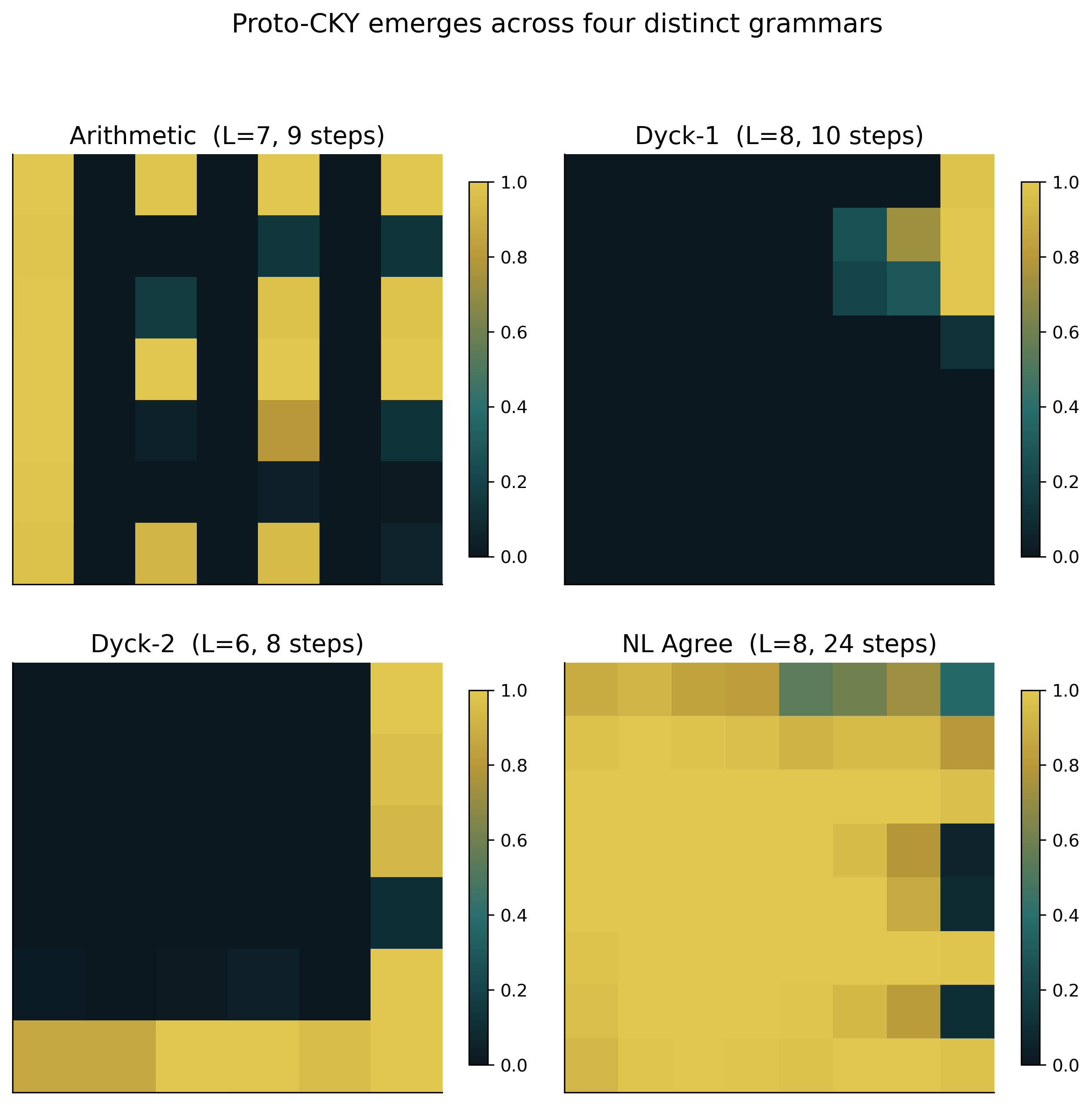
Table 1 presents the results across all six languages side by side. Grid variance exhibits a two-order-of-magnitude gap between the regular languages and the CFGs. The internal activations on the four CFGs further show systematic positive correlation with their respective CKY charts ($r \approx 0.2\text{–}0.7$).
| Language | Type | Grid variance | Pearson $r$ |
|---|---|---|---|
| $a^*$ | Regular | 0.003 | — |
| $a^* b^*$ | Regular | 0.005 | — |
| Dyck-1 | CFG | 0.101 | 0.22 |
| Dyck-2 | CFG | 0.145 | 0.25 |
| Arithmetic | CFG | 0.191 | 0.71 |
| NL Agreement | CFG | 0.204 | 0.22 |
4.3 Proto-CKY Is Not a Copy of CKY
Since Proto-CKY is functionally aligned with the CKY chart, one might ask: has the NCA simply learned to imitate the CKY algorithm internally? If so, the emergence would be less striking; it would be nothing more than a learned clone of a known algorithm.
Let us check directly. If the NCA were copying CKY, its internal activations should be highly
consistent with the CKY chart, and we should expect a correlation coefficient near 1. The
measured Pearson correlation is $r = 0.709$ (for the start non-terminal $E$, on the
representative expression id + id * id; the randomly-initialized baseline is
$r \approx -0.087$, standard deviation $0.077$). There is systematic positive correlation,
but $r = 0.71$ is far from a copy. The two correspond, but they are plainly not the same
thing (Figure 5).
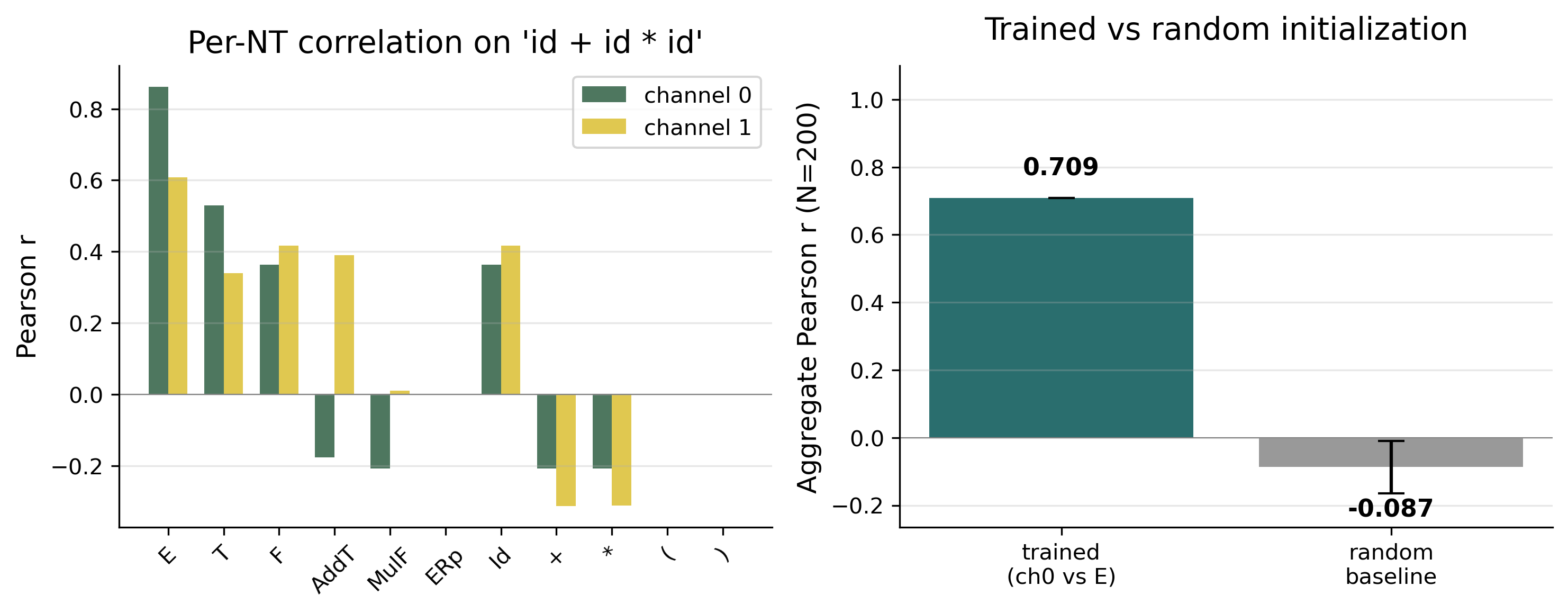
id + id * id, broken
down by non-terminal. Right: aggregate $r$ between channel 0 and the E non-terminal on
200 samples, compared to a randomly-initialized NCA baseline.
Our understanding of Proto-CKY's internal structure remains rather limited. But one thing is clear: it is not a copy of CKY. It shares CKY's function — organizing tokens into hierarchical constituents — but it does so through a different and not yet fully understood internal implementation. That two fundamentally different computational mechanisms, discrete enumeration and continuous relaxation, converge functionally is itself a striking phenomenon.
4.4 Proto-CKY Is Not a Coincidence
So far we have ruled out two alternative explanations: Proto-CKY is not architectural noise, and it is not a copy of CKY. But it could still be fragile — a coincidence that happens to appear under a particular random seed or particular hyperparameter setting.
Consider the simplest robustness check. We train the same architecture on 10 different random seeds. All 10 runs produce ordered representations; 9 of them reach 100% balanced OOD accuracy at $L = 500$, and the tenth reaches 93.3%. The Pearson $r$ measured per seed has a mean of $0.60$ (standard deviation $0.10$). In a capacity ablation, reducing the hidden dimension from $d = 16$ to $d = 4$ (shrinking the parameter count from 18,658 to 1,210, a 15-fold reduction) preserves 100% OOD accuracy at $L = 500$, and the ordered representation still appears (Table 2).
| Setting | Params | In-dist | $L = 500$ OOD | Pearson $r$ |
|---|---|---|---|---|
| Seed stability ($d = 16$, 10 seeds) | ||||
| Best seed | 18,658 | 100% | 100% | — |
| Worst seed | 18,658 | 100% | 93.3% | — |
| Mean ± std | 18,658 | 99.98 ± 0.06% | 99.33 ± 2.11% | 0.60 ± 0.10 |
| Capacity ablation (single seed) | ||||
| $d = 4$ | 1,210 | 97.4% | 100% | — |
| $d = 8$ | 4,722 | 99.6% | 100% | — |
| $d = 16$ (main) | 18,658 | 100% | 100% | 0.71 |
| $d = 32$ | 74,178 | 100% | 100% | — |
Injecting Gaussian noise ($\sigma = 1.0$) into the grid at an arbitrary step during inference, or resetting the entire state to zero, the model recovers to 100% accuracy in every case, at the cost of additional convergence steps. Structure, once destroyed, spontaneously regenerates. This is not the behavior of a fragile artifact: fragile things, once broken, do not regrow on their own (Figure 6).
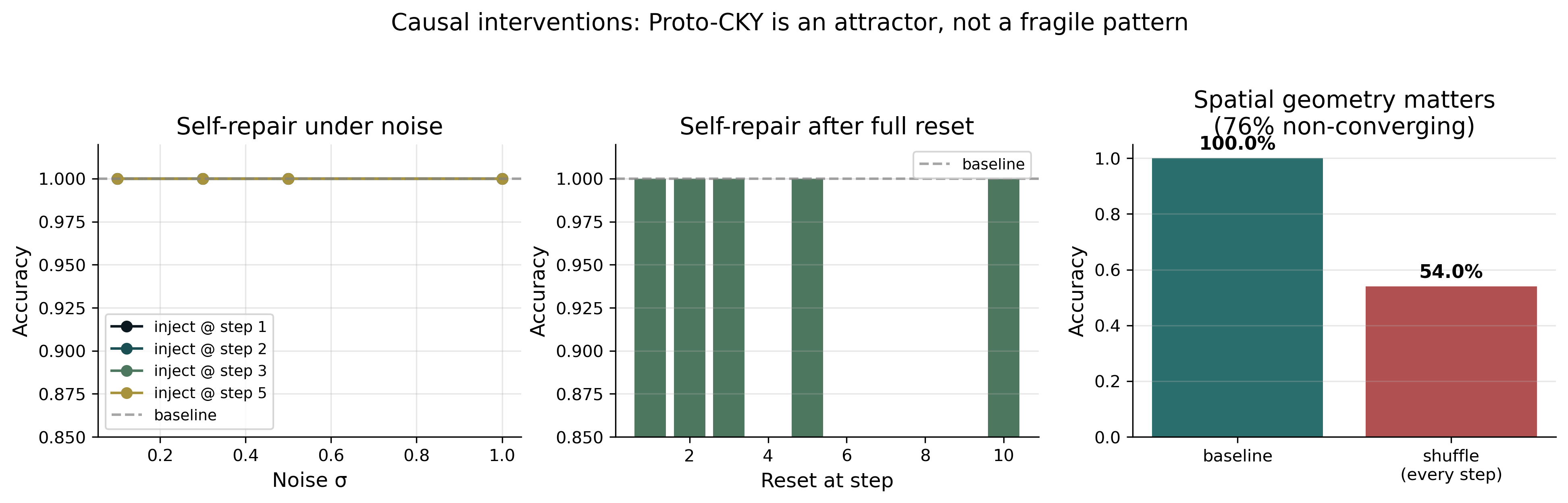
Further intervention experiments reveal what Proto-CKY depends on. Freezing 70% of the grid cells drops accuracy from 100% to 85%; freezing 50% still yields 92%; freezing 30% still yields 99%. Most cells are not irreplaceable parts; they are redundant. But randomly shuffling the spatial positions of all cells at every inference step (keeping all values intact, only changing their relative positions on the grid) collapses accuracy from 100% to 54%, with 76% of samples failing to converge. Proto-CKY's function depends on its spatial organization, not on the values of individual cells within that organization (Table 3).
| Intervention | Configuration | Accuracy | Note |
|---|---|---|---|
| Noise injection | $\sigma \in [0.1, 1.0]$, at step 1–5 | 100% | recovers |
| State reset | reset at step 1, 2, 3, 5, 10 | 100% | recovers |
| Spatial shuffle (single) | at step 1, 2, 3, or 5 | 100% | recovers |
| Spatial shuffle (sustained) | at every step | 54.0% | 76% non-conv. |
| Region freeze | random 30% of cells | 98.7% | |
| Region freeze | random 50% of cells | 92.3% | |
| Region freeze | random 70% of cells | 84.7% | |
| Region freeze | random 90% of cells | 60.3% | |
| Region freeze | upper triangle (chart area) | 85.3% | heuristic floor |
| Region freeze | lower triangle (non-chart) | 100% | |
| Region freeze | diagonal | 92.7% |
5. Discussion
5.1 What Have We Observed?
Let us step back and ask this question.
In the preceding sections we observed an ordered, spontaneously emerging internal representation. It satisfies three operational criteria; it is quantitatively correlated with the CKY chart without being equal to it; it appears stably across seeds, grammars, and capacities; it self-repairs after perturbation. We gave it a name: Proto-CKY. But from an ontological standpoint, what kind of thing have we actually observed?
Proto-CKY possesses properties that no mathematical object can have: it is continuous, finite-precision, self-repairing, and still functional when most of its cells are frozen. These are properties of a physical process, not of a symbolic system. This forces us to confront a more primitive question: what is "syntax"? In the conventions of formal language theory, "syntax" names a symbolic object: context-free grammars, derivation rules, parse trees, the CKY algorithm. It is zero-error, unbounded in capacity, and independent of any physical substrate. It is mathematically complete; its "existence" does not depend on any particular implementation.
But the word "syntax" has another use. When we say "humans command syntax," we plainly do not mean a mathematical object. We mean a processing activity that takes place on a physical substrate: finite-capacity, fooled by garden-paths, collapsing at depth 3 or more, varying among individuals on marginal grammaticality. What humans "command" is not the object in Plato's heaven. It is a physical process, one broadly aligned in function with that mathematical object but retaining a distance peculiar to physical realization.
The word "syntax" has in fact always carried two ontologically distinct meanings: one a mathematical object, the other a physical process. The two are rarely distinguished explicitly, because in the formal-language tradition the mathematical object is taken by default as the primary subject of study, and physical realization is treated as "engineering detail." But when we confront an object that has emerged spontaneously from local rules, this default ordering no longer holds. What emerges is, by definition, not and cannot be a mathematical object; it is physical.
Proto-CKY belongs to the latter category. It is not an instance of "syntax" in the mathematical-object sense. It belongs to the family where "humans command syntax" also sits: a physical process, carrying all the hallmarks of physical realization. We named it Proto-CKY because its relation to CKY is that of a physical prototype to a mathematical ideal: aligned in function, separated by a measurable distance in form.
This distance deserves to be taken seriously. If Proto-CKY were merely a numerical approximation to CKY (the same function realized at finite precision), all its properties should follow CKY's. Self-repair should not appear: a numerical approximation, once broken, does not regrow. Redundancy should not appear: every cell of CKY is independently computed, with no redundancy. Proto-CKY exhibits precisely these deviations. They tell us it is not a shadow of CKY but a different class of object: a physical process with its own structure, one that happens to align functionally with CKY.
5.2 Geometry and Dynamics
Why does Proto-CKY arise here? We cannot give a complete answer, but we can point to two necessary ingredients.
The first comes from the geometry of the 2D grid. Under a $3 \times 3$ receptive field, cell $(i,j)$ is the position that, along the shortest path, can simultaneously receive influence from token $i$ and token $j$. The upper triangle therefore becomes the natural coordinate system for token-pair interaction under this locality constraint. At the same time, the readout position $(0, L\!-\!1)$ can only access its $3 \times 3$ neighborhood. For the 1-bit supervision signal to depend on global information, the model must organize some intermediate representation on the interior grid to relay distant information. Geometry provides a natural coordinate system; local supervision forces information to traverse the grid. Together they form an inductive bias toward span-like organization.
But geometry explains only the coordinate system, not the content. Why does the system converge to an ordered state along this coordinate system? This is the second ingredient: dynamics. The self-repair experiments suggest that Proto-CKY is not a static pattern that training has "placed" in the right position; it behaves more like an attractor of a dynamical system, pulled back when displaced. The collapse under spatial shuffling further shows that the existence of this attractor depends on correct spatial structure: values can be broken, and the system recovers; but once the geometry is scrambled, the attractor itself ceases to exist. Geometry provides the coordinate system, dynamics drives convergence; neither suffices without the other.
5.3 Open Questions
Even granting the geometry-plus-dynamics framework, many phenomena remain unexplained.
The internal organizational principles of Proto-CKY are the most conspicuous open question. The converged grid displays an ordered continuous-field-like structure. Visually, one can observe a tendency toward column-wise organization, but this tendency weakens as input length grows, and the underlying mechanism remains unclear. More fundamentally: what are Proto-CKY's cells encoding? Each cell of the CKY chart has a clear symbolic meaning (a set of non-terminals). Proto-CKY's cells do not.
The CKY chart uses only the upper triangle ($i \le j$). The NCA grid has no such constraint; the lower triangle also participates in updates and information propagation. What role does the lower triangle play in Proto-CKY's function? More interestingly, the activation pattern of the lower triangle is symmetric with that of the upper triangle, yet local-freezing experiments suggest the lower triangle is in fact unnecessary for function.
Finally, and perhaps most fundamentally: Proto-CKY's constellation of properties — self-repair under noise, robustness to local freezing, fragility under spatial shuffling — evokes, in the physical picture, something closer to a crystal than to a clock. A clock's order comes from deliberate engineering, with every gear playing a precise causal role. A crystal's order comes from physical conditions: introduce impurities, and it is largely unchanged; heat it, and it melts; cool it, and it recrystallizes; but alter the lattice constant, and the same crystal will not form. This is not a rigorous theory, but it suggests a direction: perhaps the right question is not "what does each cell of Proto-CKY do?" but "what conditions make this kind of order inevitable?"
6. Conclusion
Structured, productive sequence processing can emerge spontaneously under minimal physical constraints. The form it takes, at least in the one instance we have observed, is a physical prototype, not a mathematical object.
Proto-CKY emerges under the constraints of 18,658 parameters, 1 bit of boundary supervision, and purely local interaction. It satisfies three operational criteria for syntactic processing. It appears independently on four context-free grammars and is absent on regular languages. It is quantitatively correlated with the CKY chart in function but maintains a distance in form peculiar to physical realization. This distance is not approximation error; it is information about the physical substrate itself.
Taken as a starting point, Proto-CKY turns an object that would otherwise be difficult to observe directly — namely the form in which structured sequence processing emerges in local-rule systems — into a concrete instance that can be opened in full, inspected cell by cell, and systematically ablated. On such an instance, many questions can now be asked meaningfully: what its internal mechanism specifically is; whether it generalizes to other families of formal languages; whether there are comparable properties between it and biological language processing; whether it is of the same kind as what happens inside large-scale neural language models. This paper does not answer these questions, but they can now be asked of a concrete, inspectable object.
Syntax in the physical sense, as an object of study, is something quite different from symbolic syntax. What this paper reports is one instance of it.